

October 4, 2024
Why is Asset Deduplication A Hard Problem?

Vinay Sridhara
15 min read | Security Posture
October 4, 2024
“If you cannot count it, you cannot manage it.” – Every CISO and CIO ever
Asset deduplication is a crucial challenge in exposure management (and CAASM). In today’s complex IT environments, effective management of vulnerabilities and other findings relies on accurate asset inventories to understand and mitigate potential risks. Assets from different data sources must be analyzed, deduplicated and then associated with enumerations of applications, software, users, controls, business processes, policies and more.
But deduplicating assets is far from simple, and not something you can do with a simple script. Let’s dive into why asset deduplication is such a difficult problem to solve in these contexts.
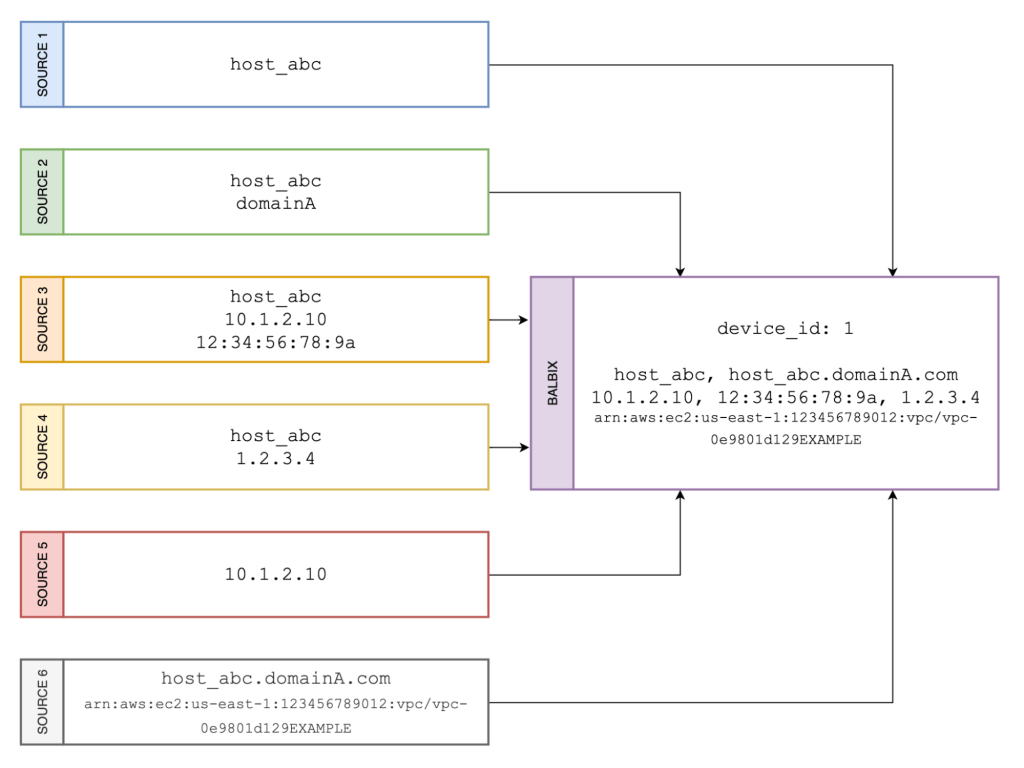
One of the core functions of any exposure management (or CAASM) platform is bringing together data from multiple sources—like CMDBs, cloud platforms, network inventories, security tools, and Active Directory (AD). Each system often has its own way of labeling and identifying assets, using unique naming conventions, data structures, and formats. This diversity makes it challenging to determine when two different data points represent the same asset.
Example: Imagine a situation where an exposure management system receives asset information from two different sources—one from a vulnerability scanner and one from an EDR tool. If the two sources list the same server under different names or identifiers, this asset might show up twice. As a result, the risk associated with this server could be counted multiple times, leading to an inflated risk score. This could push IT teams to allocate resources to mitigate a risk that doesn’t truly exist, taking their focus away from more pressing threats.
Data quality is another significant challenge. Exposure management depends on accurate data to effectively assess and manage risks, but many data sources don’t provide complete information about assets. One system might have an IP address, another might list a hostname, while a third might have a MAC address. Without a complete and consistent set of identifiers, determining if records from different systems represent the same asset becomes incredibly difficult.
Exposure management ingests data from systems like Configuration Management Databases (CMDBs) and Active Directory (AD), which are intended to maintain up-to-date records of assets. However, these systems are often riddled with stale data. A CMDB might list assets that have been decommissioned, while AD may still contain records for users or devices that are no longer active.
This stale data creates major obstacles for deduplication efforts. An old server listed in the CMDB but no longer existing in the actual infrastructure might be incorrectly marked as an active asset. Similarly, assets may have been reallocated but not properly updated in these databases. Exposure management and IT teams might end up working with redundant or outdated information, leading to incorrect prioritization of risks. This can be incredibly frustrating for the people involved and can sap away 25% of the productivity of your teams.
Modern IT environments are dynamic. Most end user computing assets are constantly moving between locations and register in your system as multiple IP addresses, often within the same hour. Your cloud infrastructure consists of virtual machines, containers, and microservices that are continuously spun up and taken down. Effective exposure management relies on a real-time understanding of these assets, but their constantly shifting nature means that deduplication efforts need to be fast and adaptable. Tracking assets that come and go frequently is challenging, creating the risk of outdated or duplicated information that impacts risk assessment.
The same asset can often be represented by different identifiers depending on the context—IP addresses, hostnames, MAC addresses, serial numbers, and more. Cloud environments in particular can lead to frequent changes in identifiers, like dynamically assigned IPs. For exposure management, accurately identifying these changing assets is crucial for maintaining a reliable understanding of risks, and multiple identifiers add layers of complexity to deduplication.
Shadow IT—unsanctioned devices, systems, or applications introduced without formal oversight—further complicates deduplication in exposure management. Assets that are not properly documented introduce unexpected discrepancies. If shadow IT is involved, exposure management teams might mistakenly interpret duplicates or overlook certain assets entirely, leading to an incomplete understanding of the environment’s risk posture.
Exposure management tools often pull data from multiple systems, requiring normalization before assets can be effectively deduplicated. Different systems use various naming conventions, abbreviations, and data structures—like abbreviating “server” as “srv” or “svr.” Without proper normalization, identical assets may appear to be completely different, making deduplication difficult. Normalizing this data is a complex process that can require significant manual effort, which doesn’t scale well for large environments.
Unlike other domains with globally unique identifiers (such as ISBNs for books), the IT world lacks universal standards to uniquely identify assets. Exposure management tools must rely on combinations of information—like IP, hostname, or MAC address—to deduplicate records. This increases the likelihood of mistakes, such as either incorrectly merging distinct assets or failing to recognize duplicates. These errors can directly impact the ability to assess and mitigate potential risks.
Applications and some types of assets, such as S3 buckets, are often identified by URLs, making it challenging to distinguish between what constitutes an infrastructure asset versus an application. For example, a URL may point to an S3 bucket used for storage (considered infrastructure) or to an internal web application critical to business functions. Despite both being identified by URLs, they serve entirely different roles, which complicates categorization and prioritization efforts.
Further complicating matters, there are cases where seemingly duplicated assets are, in fact, legitimate. Identical configurations might be deployed for redundancy purposes or high availability. Differentiating between these legitimate duplicates and unnecessary duplicates requires nuanced context, which is challenging to automate. Exposure management systems need to recognize such legitimate duplicates to avoid gaps in risk assessment.
Another related problem is determining the correct category for each deduplicated asset. Beyond simply knowing how many assets exist, effective exposure management requires a detailed understanding of the type, operating system, location, and business function of each asset. IT and cybersecurity teams need visibility into questions like: How many Windows servers do we have in the data center? How many devices belong to the finance department? How many assets are running outdated versions of an operating system? Properly categorizing each asset allows organizations to better understand their risk exposure and prioritize remediation accordingly.
However, achieving this level of categorization can be challenging due to the diversity of data sources and the lack of a unified classification scheme. Different sources may provide conflicting information about an asset’s type or role. For instance, one system might label an asset as a “Windows Server,” while another might describe it as a “Windows 10 Workstation VM” Reconciling these labels is crucial, as the inability to do so can lead to misclassification. This, in turn, can affect the exposure management strategy, with assets either misprioritized or incorrectly scoped in risk assessments, ultimately causing security gaps.
Another critical challenge in building an accurate asset inventory is defining the right filters to provide meaningful business context. Many organizations attempt to use tags from various tools to classify assets, but reconciling tags from different systems can be highly problematic. Teams across an organization often use different acronyms, naming conventions, or even make spelling errors, which leads to inconsistent tagging of assets. For example, one team might tag an asset as “Production,” another as “Prod,” while a third might use “PRD.” Although these tags may all mean the same thing, the lack of standardization can make it difficult to apply consistent filters to gain a holistic view of the environment.
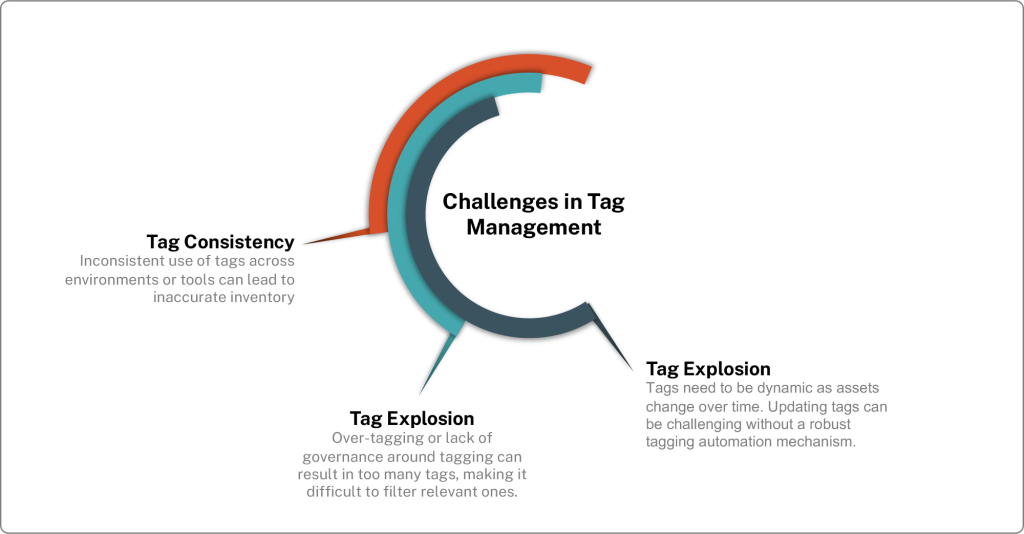
Exposure management relies heavily on filtering assets by business function, environment, location, or criticality to provide context and drive effective risk management decisions. Inconsistent or conflicting tags make it hard to create accurate views of the asset inventory that reflect the actual environment. This can lead to gaps in visibility, with critical assets either being overlooked or being miscategorized. The result is that risk assessments may fail to accurately reflect true exposure, and remediation efforts may be misdirected, creating inefficiencies and potential vulnerabilities.
Balbix uses AI to perform sophisticated deduplication for a wide range of entities, including assets, applications, users, software, and security controls. By correlating data from multiple sources, Balbix can recognize when two records represent the same underlying element, reducing redundancy and providing a unified, accurate view of the IT environment. This deduplication process goes beyond simple asset management—it touches every relevant component that contributes to an organization’s cyber risk and exposure, ensuring that IT and security teams work with the most accurate and up-to-date inventory possible.
In addition to deduplication, Balbix also categorizes assets using AI to ensure that each asset has the appropriate context for exposure management. Multiple models work in conjunction leveraging identifiers and attributes associated with assets to determine their type, geolocation, owner, and blast radius. Finally, a weighted vote across different models is conducted to determine the asset category. This approach is like how humans categorize assets.

The Balbix TAG Manager automatically deduplicates and correlates tags across various data sources and maps them to correct operational contexts and meaningful business categories. This means that similar tags—whether due to different acronyms, naming conventions, or even spelling mistakes—are reconciled and standardized to reflect their true meaning. Furthermore, users have the flexibility to configure these mappings, allowing for greater customization based on an organization’s unique requirements. By making tag management smarter and more automated, Balbix helps organizations extract the business context they need to effectively assess and manage cyber risks.
Asset deduplication in the context of Exposure Management (and CAASM) is inherently difficult due to the complex nature of modern IT ecosystems. The variability of data across multiple sources, combined with rapidly changing environments, the persistence of stale data in core systems like CMDB and AD, and the added complexities of asset categorization and filter definition, make achieving accurate deduplication a critical yet challenging task. Effective exposure management relies on accurate, deduplicated data to offer a complete view of risks, and getting this part right can significantly enhance an organization’s ability to reduce its attack surface.
Balbix tackles these challenges head-on using AI-powered approaches that ensure your asset inventory is accurate, up-to-date, and enriched with the right context for managing cyber risks effectively. If you’re ready to see how Balbix can transform your exposure management with powerful deduplication and categorization capabilities, please request a demo today and take the first step towards a clearer, more actionable understanding of your cybersecurity posture.